Генератор голоса по тексту онлайн — нейросеть бесплатно
Генератор голоса по тексту онлайн: как за минуту превратить текст в речь нейросетью. Выбор голоса, цены, бесплатные варианты и пошаговая инструкция 2026.
Генератор голоса — это нейросеть, которая превращает текст в реалистичную речь: вставляете текст, выбираете голос, скачиваете аудио. В 2026 году сгенерировать голос по тексту онлайн можно за минуту — бесплатно для теста и от 3,50 ₽ за 1 000 символов на русском. Ниже разберём, как это сделать пошагово, какой генератор выбрать под вашу задачу — видео, курс, подкаст — и где нейросеть всё ещё проигрывает живому диктору.
Что такое генератор голоса по тексту
Генератор голоса по тексту — это онлайн-сервис, который принимает на вход текст, а на выходе отдаёт аудиофайл с озвучкой. В англоязычной среде технологию называют TTS (Text-to-Speech), в русскоязычной — синтез речи. Современные генераторы построены на нейросетях: они не склеивают заранее записанные фрагменты, как старые «голоса навигатора», а создают звук с нуля, учитывая контекст и интонацию. Результат сложно отличить от записи с микрофоном.
Как сгенерировать голос по тексту онлайн за 4 шага
Покажу процесс на примере GenVoice — от регистрации до готового аудиофайла. Весь путь занимает 3–5 минут.
Шаг 1. Зарегистрируйтесь
Перейдите на app.genvoice.ru — регистрация по почте или через Яндекс. После регистрации на балансе 2 000 символов: этого хватит на несколько синтезов, чтобы оценить качество голосов до любой оплаты.
Шаг 2. Выберите голос
Откройте раздел «Синтез речи». Справа — библиотека голосов с кнопкой прослушивания у каждого. Послушайте 3–4 варианта: тембры сильно различаются, и «свой» голос вы услышите сразу. Если хотите озвучивать собственным голосом — загрузите аудиообразец в разделе «Мои голоса». Достаточно 3 секунд чистой записи, и клон появится в списке через пару секунд.
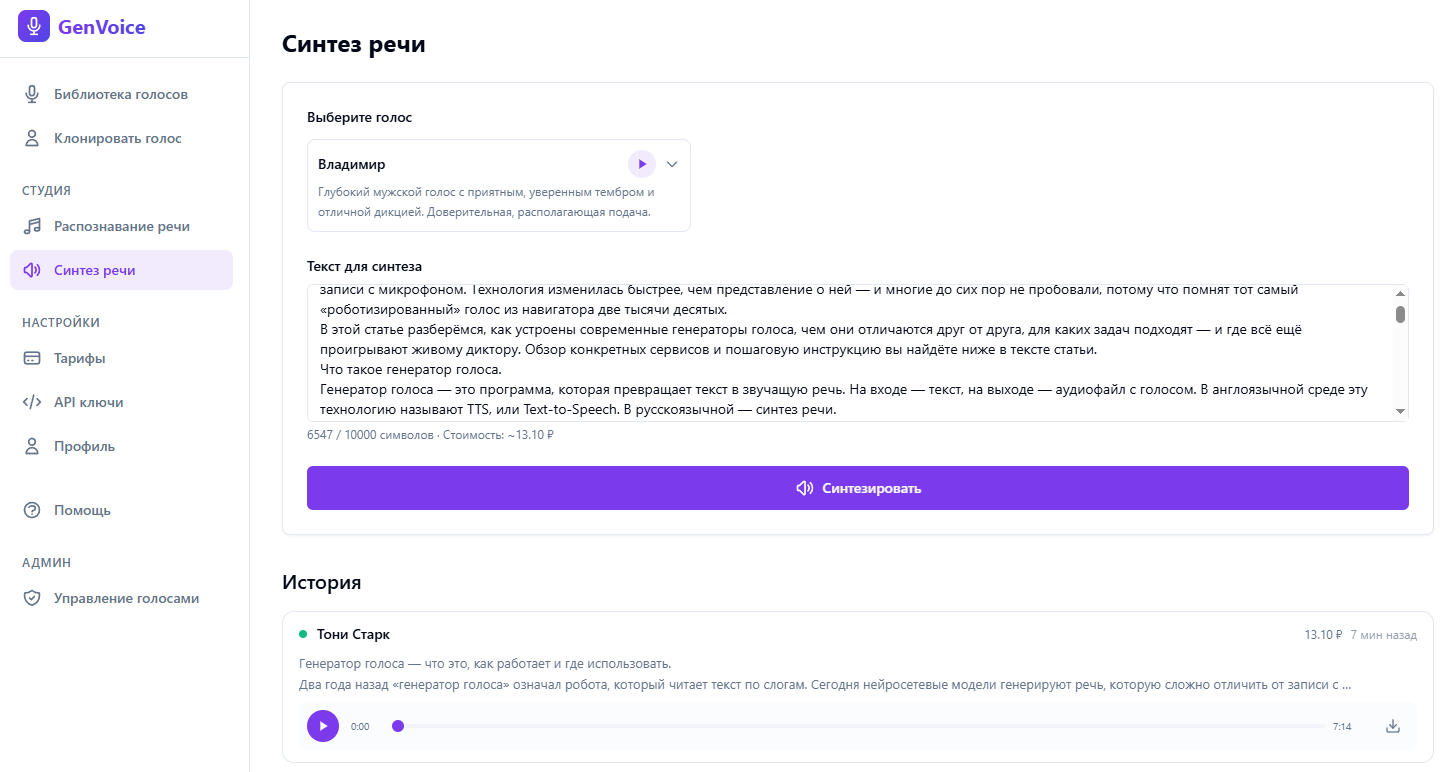
Шаг 3. Вставьте и подготовьте текст
Вставьте текст в поле ввода. Перед генерацией стоит адаптировать его для устной речи: раскрыть сокращения, расставить ударения знаком + для неоднозначных слов (зам+ок, м+ука), убрать конструкции, тяжёлые на слух. Подробно о подготовке текста — в пошаговой инструкции по озвучке.
Шаг 4. Синтезируйте и скачайте
Нажмите «Синтезировать». Результат появится через несколько секунд — послушайте прямо в интерфейсе. Если всё устраивает, скачайте в WAV или MP3. Все синтезы сохраняются в истории: можно вернуться к любому, переслушать и скачать повторно.
Сгенерировать голос в GenVoice → 2 000 символов на балансе при регистрации — хватит на несколько тестовых озвучек. Нужна просто озвучка текста онлайн? Начните здесь.
Можно ли сгенерировать голос бесплатно
Частично — да. Почти у всех генераторов есть бесплатный режим или стартовый баланс, но с ограничениями: лимит символов, водяной знак или урезанный выбор голосов. Полностью бесплатного профессионального генератора без лимитов не существует — качественный синтез требует вычислительных ресурсов, и рано или поздно вы упрётесь в тариф.
| Сервис | Что даёт бесплатно | Подводные камни |
|---|---|---|
| GenVoice | 2 000 символов на балансе при регистрации | Баланс не возобновляется, дальше — оплата по факту |
| Zvukogram | Бесплатный режим без регистрации | Ограниченный набор голосов, на части — «роботизированность» |
| ElevenLabs | 10 000 символов/мес | Водяной знак, оплата в долларах, карты РФ не принимаются |
| Яндекс SpeechKit | Пробный грант в Yandex Cloud | Нужны технические навыки, нет веб-интерфейса |
Совет: используйте бесплатный лимит именно для теста качества на вашем тексте и языке, а не для финального продукта. Так вы поймёте, какой генератор звучит лучше под вашу задачу, не потратив ни рубля.
Какой генератор голоса выбрать: сравнение 5 сервисов
На рынке десятки TTS-сервисов, но для русского языка рабочих вариантов значительно меньше. Вот пять генераторов, которые стоит рассмотреть, — кратко, с честными плюсами и минусами. Если нужен развёрнутый разбор, у нас есть отдельный обзор сервисов озвучки текста.
- GenVoice — российский нейросетевой синтез с клонированием от 3 секунд. Цена 3,50–5 ₽ за 1 000 символов, оплата картой РФ, есть API. Минус: пока два языка (русский, английский) и нет SSML.
- Zvukogram — один из первых российских TTS, есть бесплатный режим без регистрации. От 1 ₽ за 1 000 символов. Минус: нет клонирования, качество зависит от голоса.
- ElevenLabs — мировой лидер качества на английском, мощное клонирование. От $5/мес. Минус: карты РФ не принимаются, русский слабее английского.
- Яндекс SpeechKit — облачный TTS с API и SSML. От 1,6 ₽ за 1 млн символов на объёме. Минус: только через Yandex Cloud, нет клонирования и веб-интерфейса.
- SteosVoice — профессиональное клонирование для студий. Синтез от 1 ₽. Минус: для клона нужна запись от 15 минут (у GenVoice — от 3 секунд).
Сводная таблица
| Сервис | Цена (1 000 симв.) | Клонирование | Русский язык | Оплата РФ |
|---|---|---|---|---|
| GenVoice | 3,50–5 ₽ | Да, от 3 сек | Оптимизирован | Да |
| Zvukogram | 1–4 ₽ | Нет | Средне | Да |
| ElevenLabs | ~5 ₽ (при $5/мес) | Да | Да (хуже EN) | Нет |
| Яндекс SpeechKit | от 1,6 ₽ | Нет | Да | Да |
| SteosVoice | от 1 ₽ | Да, от 15 мин записи | Да | Да |
Идеального сервиса нет. Нужен русский язык и клонирование — GenVoice или SteosVoice. Важна мультиязычность — ElevenLabs. Для API-интеграции в продукт — Яндекс SpeechKit. Для быстрой бесплатной озвучки без регистрации — Zvukogram.
Генератор голоса по типу: женский, мужской, детский, персонаж, свой
Чаще всего ищут не «генератор голоса вообще», а голос конкретного типа. Современные генераторы дают библиотеку из десятков тембров плюс возможность клонировать любой голос. Вот как закрыть самые частые запросы.
Женский и мужской голос
Базовый выбор любого генератора. В библиотеке GenVoice есть и женские, и мужские тембры — дикторские, тёплые, нейтральные. Послушайте 3–4 варианта каждого пола: разница в подаче сильнее, чем кажется по описанию. Для рекламы берут энергичные тембры, для обучения — спокойные и разборчивые.
Детский голос
Детский голос востребован для мультфильмов, сказок, обучающего контента и игр. Это отдельная задача: не каждый генератор умеет звучать по-детски естественно. Как подобрать и настроить такой тембр — разобрали в статье про озвучку текста детским голосом.
Голос персонажа
Для игр, анимации и роликов нужен не нейтральный диктор, а характерный голос — злодея, робота, сказочного героя. Подобрать выразительный тембр и задать ему нужную подачу можно — подробности в гайде про озвучку голосом персонажа.
Свой голос (клонирование)
Если хотите, чтобы текст звучал именно вашим голосом, — это клонирование. В GenVoice достаточно образца от 3 секунд, и нейросеть создаст цифровую копию вашего тембра. Как это работает и где применяется — в материале про клонирование голоса нейросетью.
Сколько стоит сгенерировать голос: генератор vs диктор
Цифры, чтобы сориентироваться. Расчёт на примере GenVoice (3,50–5 ₽ за 1 000 символов) и средних ставок дикторов на фрилансе.
| Задача | Объём | Генератор | Диктор |
|---|---|---|---|
| YouTube-ролик (10 мин) | ~9 000 символов | 32–45 ₽ | 5 000–15 000 ₽ |
| Онлайн-курс (20 уроков) | ~60 000 символов | 210–300 ₽ | 40 000–80 000 ₽ |
| 100 карточек товаров | ~50 000 символов | 175–250 ₽ | 50 000+ ₽ |
| Аудиоверсия статьи | ~10 000 символов | 35–50 ₽ | 3 000–8 000 ₽ |
| Подкаст (30 мин) | ~25 000 символов | 88–125 ₽ | 15 000–30 000 ₽ |
Разница — в сотни раз. Но это не значит, что генератор «лучше»: это два разных инструмента. Генератор — для масштаба и скорости, диктор — для уникальной подачи и эмоциональной глубины. Частый подход — гибридный: нейросеть для черновиков и массового контента, диктор — для флагманских проектов.
Когда генератор голоса не подходит
Честный разговор о границах технологии. Нейросетевой генератор — мощный инструмент, но не универсальный.
- Эмоциональная драматургия. Нарастающее напряжение, шёпот, смех, сарказм — нейросеть пока не справляется. Аудиоспектакли и имиджевые ролики крупных брендов — задача для диктора.
- Живые диалоги. Два персонажа, реагирующие друг на друга и перебивающие, — не для генератора: каждая реплика создаётся отдельно, без контекста собеседника.
- Пение и декламация. Генератор — про речь, не про вокал. Для пения есть отдельные инструменты (Suno, Udio).
- Идеальная точность с первого раза. Иногда модель ставит ударение не туда. Это решается подготовкой текста (знак
+, пунктуация для пауз), но требует пары минут внимания.
Если задача попадает в эти категории — выбирайте живого диктора или гибридный подход: черновик нейросетью, финал в студии.
Как нейросеть генерирует голос (кратко)
Под капотом генератор проходит несколько этапов: анализирует текст, расставляет ударения и паузы, строит «чертёж» звука (мел-спектрограмму) и превращает его в звуковую волну. Старые сервисы работали на конкатенативном синтезе — склеивали записанные фрагменты, отсюда «роботизированность». Современные модели (WaveNet, VITS, XTTS v2) генерируют звук с нуля и учитывают контекст предложения, поэтому речь звучит естественно. Если хотите глубже разобраться в технологии — читайте материал про синтез речи.
Частые вопросы
Как сгенерировать голос по тексту онлайн? Зарегистрируйтесь в сервисе синтеза речи, вставьте текст, выберите голос из библиотеки и нажмите «Синтезировать». Через несколько секунд получите аудиофайл, который можно скачать в WAV или MP3. В GenVoice весь путь от регистрации до готового аудио занимает 3–5 минут, на балансе сразу 2 000 символов для теста.
Есть ли генератор голоса бесплатно? Да, но с ограничениями. GenVoice даёт 2 000 символов на балансе при регистрации, ElevenLabs — 10 000 символов в месяц с водяным знаком, Zvukogram — бесплатный режим с ограниченным выбором голосов. Полностью бесплатных профессиональных генераторов без лимитов нет: качество и объём всегда упираются в тариф.
Генератор голоса хорошо работает на русском языке? Российские сервисы (GenVoice, Zvukogram, SteosVoice, Яндекс SpeechKit) обучены на русской речи и звучат естественно. Зарубежные вроде ElevenLabs поддерживают русский, но он заметно слабее английского. Для русскоязычного контента выбирайте генератор, оптимизированный под русский, и всегда слушайте демо перед оплатой.
Какой генератор голоса выбрать под свою задачу? Для русского языка с клонированием — GenVoice или SteosVoice. Для мультиязычности — ElevenLabs. Для интеграции в продукт через API — Яндекс SpeechKit. Для быстрой бесплатной озвучки без регистрации — Zvukogram. Универсального лидера нет: выбор зависит от языка, бюджета и нужен ли вам собственный голос.
В каком формате можно скачать сгенерированный голос? Большинство генераторов отдают WAV и MP3. WAV — без сжатия, для профессионального монтажа и студийной обработки. MP3 — лёгкий формат для веба, мобильных устройств и быстрой загрузки. В GenVoice доступны оба, этого достаточно для YouTube, презентаций, подкастов и аудиокниг.
Хотите оценить качество? Сгенерируйте голос в GenVoice — 2 000 символов на балансе при регистрации. Сравните с диктором сами.
Озвучьте свой текст прямо сейчас
Первые ~2 000 символов бесплатно. Выберите голос, вставьте текст — и получите готовую дорожку за минуту.
Перейти в редактор синтеза